FaST is the most interesting organizational practice I’ve learned about in a while. Today I share what FaST is, and explore whether it’s worth experimenting with. TL;DR? Quite compelling, but still experimental.

What is Fluid Scaling Technology (FaST)?
FaST is an agile software variant. FaST focuses on self-organization within very large teams. These large teams are called Collectives. They can be a few people, to as many as 150 people1.
Twice a week, the Collective meets. At the meeting:
- Team members show and tell what progress they’ve made.
- The product leader reiterates the vision and sets direction. They give context on the top projects. They introduce new priorities as work completes, or priorities change. And typically they show the priorities in a visual way, on a wall or virtual equivalent.
- People within the Collective self-organize and self-select into smaller teams to deliver the top priority work.
The most interesting part of FaST is these self-organizing teams, so let’s describe them in a little more detail.
Every meeting, people volunteer to lead teams, and people volunteer to participate in those teams. When someone volunteers to steward a team, they step forward and say, “I’m going to work on [one of the top projects]”. People then join the teams that have been created and work in that area. The minimum team size is two, so you need people to “vote with their feet” to form the team.

The teams formed do not have to be around the priorities that product has laid out. For example, a team can form around improving the deploy pipeline, or improving monitoring for some flaky services.

Outside of the hour a week in meetings, people spend most of their time in their self-selected, self-organized teams. Theoretically, you could change teams twice a week. But in practice, people end up figuring out who they like to work with, and teams tend to settle down after the first month or so. They remain fluid enough that people can move as business needs shift, or people with expertise are needed in different areas. Moving teams is an expected, low-effort change. So what this means is that during the Collective meetings, there is a pattern of people recreating their teams, but the composition tends to not change as much as you might imagine.
There are a lot of other details like how bugs and on-call are handled. I’ll cover some of these topics later. But the basic core of FaST is these self-selecting teams, working within a larger Collective, on projects. The Collective meetings are structured, and focused on giving context on the needs of the business, and communicating progress against those priorities.
Summary of differences
FaST is much different than the way most agile software organizations run today. Here are the differences as I see them:
| Common practice (SCRUM, Kanban, or “Lightweight Agile”) | FaST | |
| Meeting density | Medium to High Varies from company to company, but commonly daily standups, demos, grooming, estimation, retros, etc). | Low Two, half-hour meetings a week. Others as desired. |
| Ability to scale | Unit of scaling is the team. Growing and splitting and creating teams (and their areas of responsibility) is a major focus of management. As business priorities change, requires reorgs to reflect the change in priorities. | Unit of scaling is the Collective. Practically speaking, the number of tracks of work will scale similar to common practice. However, adding people and shifting flows of work is more fluid and self-organizing. Less challenges with “too small” or “too large” teams. Less concerns about viability of teams, and matching teams to areas of responsibility. Untested at very large companies, but theoretically seems sound. |
| Code ownership and expertise alignment | Strict code ownership, which helps divide the world into what individuals can master. Good alignment of incentives because people work in their area. Challenges are to make sure each team can maintain and operate its codebase. Moving responsibilities tends to be painful. Changing business priorities often results in reorgs. Practices can be decentralized and fragmented, although this can cause challenges. For example, you can let teams choose their own programming languages, choose different ways of working, and different coding styles. | Shared code ownership. Requires good standards, skilled team or good review practices. Changing priorities is less difficult. Reorgs are almost non-existent, unless you’re changing Collective boundaries. (Think of how much management time is spent in reorgs!) Practices need to be more standardized, or you will have problems. Standardizing practices is a good thing, so incentives are in the right place, but failure mode is probably worse. |
| Architectural patterns | The ideal architecture is microservices. Large monoliths need to be well-factored. Generally messy outside microservice environments. | I would expect FaST to be more agnostic about architecture. Should work with monolithic codebases or microservice environments. And with a blend. Should make moving to microservice environments more gradual. |
| Rollout patterns | Strict code ownership tends to require organization-wide design of which team owns what. Implementation of these changes is always big-bang. Requires disruptive, large reorgs. | Can be done incrementally. You can start with a team or two, and gradually add additional teams to it if it works. Reorgs should be infrequent. Will still happen at a Collective level, but that should be less frequent. |
| Alignment mechanisms | Typically use OKRs, all hands meetings, and written communication to align people. | The Collective meetings are a built-in All Hands meeting twice a week, where you reinforce goals and set context for the team. If leadership treats that meeting seriously, seems very high leverage. |
| Employee retention | Practices can range from feature-factory grind and top-down, high-control environments, to high performance teams that understand their business context and customers, and continually deliver value for their business. Thus, retention will vary significantly by company. | I expect practices can vary, similar to common agile practices. However, FaST lends itself to employee retention because it is aligned with intrinsic motivation. Employees can choose who they work with, what they work on, and get reinforcement that their work matters. I would expect this to result in better overall satisfaction. One challenge might be politics. Self-governed groups sometimes deal with conflict poorly, so that could backfire. |
As you can see, FaST is a very different approach than what most companies are doing today.
So what are the tradeoffs?
As I see it, these are the tradeoffs of FaST agile:
- FaST may offer better organizational scalability
- FaST can be experimented with incrementally
- FaST should result in fewer reorgs
- FaST makes it easier to respond to changing priorities
- FaST could be better for intrinsic motivation and retention
But…
- Many environments are incompatible with FaST
- You might have to manage self-management
- FaST requires a lot of work
- FaST can run counter to a desire to allocate people to areas
- The FaST materials are full of jargon
We’ll discuss each of these in turn.
FaST may offer better organizational scalability
When you scale organizations, you typically do so by scaling them “horizontally”. You grow the organization a team at a time. Each of these teams own a slice of the product, and you often have a platform organization that makes the product teams more effective.
The complexity of the organization explodes as the number of people increases. If you have ten people in engineering, they can all communicate with each other. A hundred people in engineering cannot all talk with each other. And the codebase won’t fit in any individual’s head. So you segment this complexity into teams, and each team has an area they can focus on.
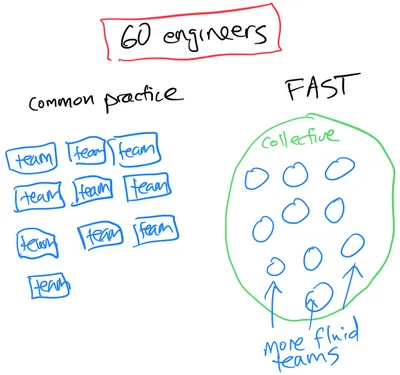
FaST is interesting because it is an attempt to scale organizations “vertically”. Instead of adding more teams, FaST attempts to make bigger teams, called Collectives. The Collectives still own code, but the self-organized teams within that Collective do not. And you do still have to segment communication. But the teams are more dynamic and continually evolved. Instead of reshaping teams through reorgs, it is a continual, expected part of the way you operate.
Team size is a familiar topic for many heads of engineering. How large should teams be? Let’s delve into this topic a bit, as it helps us understand how FaST claims to scale better.
How large should teams be?
When you spend time around VP of Engineering folks, occasionally the topic of engineering team size will come up. You’ll hear arguments for small teams, and arguments for large teams. Both sides have merits.
Advantages of small teams
- Less coordination and communication overhead within the team.
- Can move quickly as a result.
- Less streams of work, so easier to focus and produce results.
- Easier to manage.
Advantages of large teams
- Flatter organization. An engineering organization with 150 engineers in it will have 3-4 directors with ten-person teams. It will have 6-8 directors and 1-2 VPs with five-person teams. Where does the confusion in an organization come from? Probably the leadership, so large teams can reduce confusion.
- More resiliency. Someone can take vacation and the team can continue just fine.
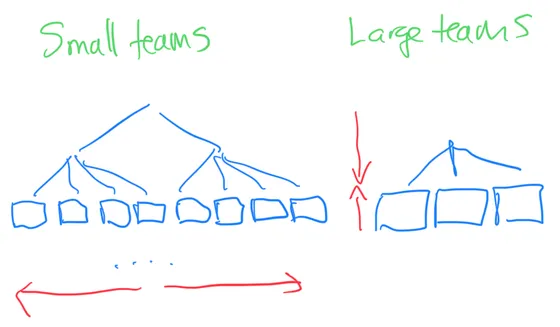
So small teams are great within their team, but less ideal because there are so many of them that it increases organizational complexity. Larger teams are better for overall organizational complexity, but less ideal for performance within each team.
The approach many leaders take is to make large teams that focus on fewer streams of work. This reduces internal team complexity, and also reduces organizational complexity.
You can look at FaST as an approach which tries to achieve even greater organizational simplicity through ridiculously large teams. And it tried to get the benefits of having small self-assembling teams as well.
Scaling organizations is challenging work
Much of my consulting business is helping organizations deal with scale. There are several phases of scaling challenges organizations run into.
The first barrier is typically at the 15-25 engineer mark. This is the time that your amoeba has gotten too big, and needs to split. You see these types of problems:
- Communication channels become ineffective.
- Engineering starts having delivery and/or quality problems.
- Managers or leaders feel overwhelmed. Adding more people will make it worse, not better.
And a second barrier is at around sixty engineers. At this point, you start seeing a lot more coordination problems:
- Cross-team projects rarely are successful.
- Product work swamps platform teams, or vice versa.
- Inability to complete large initiatives.
I’ve seen brilliant people fail again and again to navigate these step-order changes in organizational complexity. My hunch is that these step order increases in complexity correspond to when you add an additional layer of management.
Growing engineering organizations is a real skill. It requires a deep understanding of how organizations and people work. You learn about things like:
- Coordination models to get groups of people to work together.
- Stream-aligned teams versus functionally designed teams.
- How to do reorgs, where you shift people and code around as business priorities change.
- How to divide products into areas of technical responsibilities overlapping with product investment.
- Setting up communication channels around teams.
- Setting up on call and reliability programs to support your product effectively.
- Setting up platform organizations and developer experience initiatives to combat complexity.
- Etc.
Even if you have people with this expertise, it requires a lot of effort from your management team to deal with scaling. So if FaST can scale better, you’ll unlock a lot of the potential of your management team to focus on something else. And, because your step-order changes occur so much less frequently, you could potentially be making your organization much easier to manage.
A thought experiment around FaST agile
So, imagine you could scale team size. Instead of teams being five or ten people, what if you could have effective twenty-person teams? Or sixty-person teams?
On the face of it, this is a ridiculous proposition. Teams that large are not effective. Even twelve-person teams are a stretch. I sometimes see the resumes of people who have had twenty or thirty people report to them. My immediate reaction is to think they worked at a terrible company. Having that many direct reports is an “organizational smell”.
The central premise of FaST agile is that if you add self-organization, and self-selecting teams within this larger Collective, you can scale your teams more horizontally. Each team (FaST calls them Collectives) can be much larger. And then the teams people work with on a day to day basis are self-assembled within those Collectives.

If the larger Collectives were effective, they would reduce organizational complexity significantly. The typical software startup could go years longer before having to divide up into areas of responsibility. The codebase wouldn’t need to be rigorously segmented out into areas that each team owns. This would free up significant management time that managers could use to focus on the product and teams.
So this is the central thing we need to test: does self-assembling, and self-organization offer a way to operate that is as effective as smaller, designed teams?
If it does, then it will offer a way to scale organizations that is potentially an order of magnitude better at scaling organizations. Why that much? Let’s compare an organization growing with teams of size six people versus an organization scaling with “teams/Collectives” of size sixty people.
| Org size | How many six person teams (conventional teams) | How many Collectives (FaST) |
| 18 people | 3 | 1 |
| 60 people | 10 | 1 |
| 90 people | 15 | 2 |
| 120 people | 20 | 2 |
| … | ||
| 300 people | 50 | 5 |
There are a lot of assumptions built into this argument, and you might be able to poke some holes in it. But even if you do, FaST is essentially allowing for a larger organizational unit to own an area of the product and codebase.
FaST is new, so there isn’t a ton of evidence right now about whether FaST teams operate as effectively as conventional agile teams. But I suspect the answer to that question is yes. I have a couple of reasons to believe that. First of all, Jim Shore’s preliminary experience with it was quite positive, and he’s someone I trust.
A second reason I am bullish on FaST is that I’ve had some experience with large groups of people doing self-organization. And I was surprised at how well it worked. And I have some experience with FaST, and found it to be an effective approach, though I didn’t do it in a large Collective.
In small companies, of course, you see a lot of self-organization. But as companies grow, you standardize things and remove self-organization except within teams. However, one of the most interesting experiments I’ve been a part of was a large-scale self-organization event at New Relic. We redesigned all of our teams, and asked everyone in fifty software teams to select which team they wanted to be a part of. We had constraints on the skills needed for each team, and had defined what everyone needed to own. It ended up being way more successful than anybody anticipated, even us organizers.
So although the jury is out on this, my hunch is that this practice has a lot of potential in the right contexts.
FaST can be experimented with incrementally
This isn’t mentioned in the FaST materials, but one thing that jumped out at me as being interesting about FaST is that you can experiment with it incrementally.
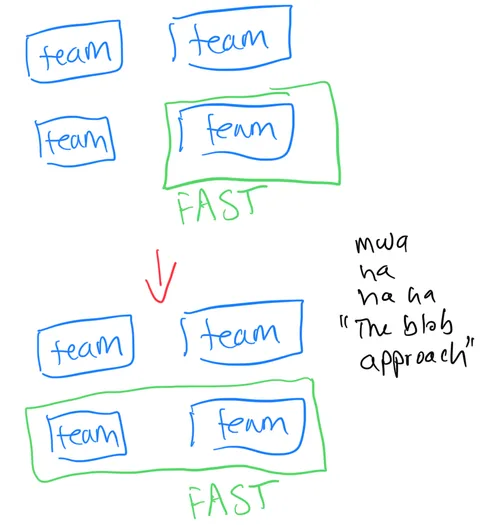
You can implement FaST Agile on one team as an experiment, and then use a blob approach where you swallow additional teams over time. If it goes well, continue to swallow additional teams. If it doesn’t, abort the experiment.
FaST should result in fewer reorgs
Change happens in organizations. Priorities shift, people leave, areas of the product have unexpected growth. Previous technical decisions bite you and you have to do additional work. New opportunities arise that require investment.
All of these things have an impact on the structure of your organization. You have a set of teams, each of which have their own areas of ownership. As this change happens, you refactor your organization over time to perform the best you can. These refactorings are “reorgs”, and in growing organizations, they can happen frequently!
Reorgs should be a lot less frequent with FaST. The unit of reorganization is so large that you shouldn’t have to do it as often.
A potential downside of this is that you don’t have teams with defined areas of responsibility. So you could have a diffusion of responsibility and have a poorly maintained code commons. (We’ll talk about this a bit later)
FaST makes it easier to respond to changing priorities
When priorities change in conventionally structured teams, you have teams set up to do the work. If that team structure doesn’t support the new priorities, you have to refactor your organization.
For FaST, changes in priority are more fluid and continuous. As long as the responsibilities lie within the Collective, the teams just organize themselves around the work, and it’s like another day.
The Collective meeting structure also makes changing priorities less dramatic. You essentially have a built-in All Hands twice a week. At the Collective meetings, you can continually communicate context and educate your team on your customers and market. This should help keep your team better aligned.
When I contrast that approach to something like Quarterly OKRs, it seems more fluid and like it would do a better job of aligning people. It does require a committed effort from the product leader to continually share context and priorities. But some of the best teams I’ve been a part of had a product leader acting in this fashion, so I suspect this is time well spent.
FaST could be better for intrinsic motivation and retention
Many teams can feel like their process is designed as tools to control people. And it can feel like working on an assembly line.
FaST embraces self-organization as a fundamental component of its design. It’s so fundamental, it won’t work without self-organization. It requires a completely different toolkit for management, and it’s mostly (though not completely) incompatible with top down, hierarchical approaches.
Daniel Pink famously outlined three aspects of intrinsic motivation:
- Autonomy – A desire to be self directed, which increases engagement over compliance.
- Mastery – The urge to get better skilled.
- Purpose – The desire to do something that has meaning and is important. Businesses that only focus on profits without valuing purpose will end up with poor customer service and unhappy employees.
With FaST, you’re able to self-direct your work, helping you feel autonomy. You’re able to choose to focus on work that improves your skills, achieving a sense of mastery. And you’re constantly reminded of how your work is connected to what’s important for the business, helping you feel a sense of purpose. So although it’s not guaranteed, I see a potential for organizations implementing FaST to see high retention rates.
Self-organization also provides some handy signals that can keep a community of people working better together. The “jerk manager” type of person gets a signal that their behavior isn’t welcome. How? They step forward to lead a team, and say the work they want to do. If nobody joins their team, the work doesn’t happen, and the team doesn’t form (teams have a minimum of two or three people on them, or they don’t happen).
Self-organization also allows people to deal with painful aspects of work that may not get attention in other companies. For example, if the test suite is terrible, someone can step forward to lead a team fixing that issue. It’s perfectly reasonable to do work that isn’t explicitly a business priority. But it’s in the open, and others have to join in for it to happen. This can help avoid feeling like you’re in a feature factory.
Finally, you’re able to choose the people you work with every day. When I’ve seen self-organizing teams in the past, this was an unexpected benefit: people chose to work with people they wanted to work with. And those teams were much stronger than I expected.
The thing this all would be balanced against is any new pains people would experience with FaST. One challenge might be with informal power dynamics, or potential politics.
Many environments are incompatible with FaST
Because FaST is so new, it is riskier to implement. FaST won’t make sense in every situation. And there are more unknowns. It’s best to think of it as an experimental approach.
Which environments are most conducive to trying FaST out? And where should you avoid FaST?
The more qualities from this list your company has, the better the fit for FaST:
- An interest in management innovation and experimentation.
- High trust, low-fear environments. Or at least a desire to avoid command and control in leadership.
- A good guide or facilitator of the process. Someone who can run an effective Collective meeting, set up the process, evaluate and actively manage it. Someone who understands organizational dynamics and how humans in groups work together. (You could hire me for this).
- A medium to high rate of change in priorities. FaST is less useful if priorities aren’t shifting.
- A team that is collaborative, self-directed, high-performing, and continuously learning.
- A leadership team that can figure out its priorities.
- You have a product leader who can talk about the priorities and business context at each Collective meeting. And they can communicate effectively.
The less these traits are true, the more headwinds you’ll face with FaST. I don’t think you need to be in a perfect environment for it. In some ways, I think wanting to be these things is more important than actually being these things. So perhaps the most important success factor is that leadership is on board with making space for it.
You might have to manage self-management
Self-organizing systems can work effectively. But they aren’t free. They are more like managing a community.
You’ll need to create constraints and means to incenvitize the right behavior. And you’ll need to carefully watch and manage to make sure things don’t go off-track.
Any organization can have bad actors, or people that aren’t aligned with the interests of that community. I remember once talking with an engineer who told me (I kid you not) that they didn’t think they had an obligation to produce value for their employer. Some engineers might want to focus on things that develop their skills or make them a more valuable employee, rather than things that are good for the company that employs them.
With FaST, you are signing up for managing a community of people.

In conventional situations, the hierarchy makes clear who is responsible for this. In FaST, I suspect it would be easy to try and avoid conflict and “let the members figure it out”. This could result in informal power networks dominating in a sort of tyranny of structurelessness. If you do use FaST, this is something I would guard against.
The other extreme would be to not let the group figure problems out, and to have management handle it completely. This could also be harmful.
So FaST will require good facilitation, careful observation, and occasional intervention.
FaST requires a lot of work
The biggest reason you might not want to experiment with FaST is that there is a lot of hidden work with FaST. It requires a lot of change in your organization, to an unfamiliar way of operating.
You can compare FaST to working in a new computer programming language. The new language seems promising because it has so many new ergonomic features that it seems way better than anything you’ve seen before. But, you don’t have frameworks and libraries written in this new language. So you’ll have to build a lot of it yourself.
So the biggest disadvantage of FaST is that it’s not a well established practice. You’ll need to make up a lot of things to deal with incompatibilities between how FaST operates, and conventional practices. Here are some examples:
Someone may undo all of your work
FaST is incremental, so the cost of trying it out is low. But honestly a lot of leaders have their own approaches, and may see FaST as weird and non-standard. So a change in leadership can result in completely eliminating all the work you’ve done to create this innovative system. That’s just a practical downside.
How does performance management work?
On conventional teams, you have a manager who oversees the work, and coaches individuals. You have performance reviews, and if someone isn’t a good fit, the manager can intervene. Although there are problems with performance reviews, most people understand how they work, and they serve a purpose in the organization.
On FaST teams, there isn’t really an obvious way to do performance reviews. Does the person’s manager even know what they’re doing or how they’re working? You can’t even evaluate “teams”, because they are transitory.
So the whole notion of performance management needs to be reinvented. While that may be a good idea anyway, it’s something that will require thought, and invention.
What is the role of engineering managers in FaST?
There are a lot of ways to structure an engineering manager role. I generally recommend having the engineering manager responsible for project management because it gets them to work side by side with their team, without putting them in an area where the power differential causes problems. There are a lot of valid ways of defining the engineering manager role, but that’s one I tend to gravitate to.
In FaST, the engineering manager role is less clear. You don’t have long-lived teams, so it’s harder for the engineering manager to work side by side with their direct reports.
You could have engineering managers lead the self-assembled teams. Or you could have them be pure people managers. Or you could have them be player-coaches.

All of these have tradeoffs, and some pretty big downsides. FaST seems to diminish the need for as much engineering management. You still need people to hire, do performance management, and oversee process. But maybe not as much as in a conventional organization? I’ve seen many organizations suffer because they don’t value management as a discipline. But I would guess that FaST organizations need less management.
I’m really curious to see if this plays out, and want to hear from organizations that experiment with FaST. What do you do with management?
How will you ensure code quality without areas of ownership?
Code ownership provides natural incentives for keeping code quality high. It’s in your self-interest, because your future self has to work in your present code.
In a shared code ownership situation, you have to go to greater lengths to ensure code quality. My recommendation would be pairing or mobbing as a required practice.
You’ll also need stronger standards for code patterns. You’ll need code linting. And you’ll need some sort of architectural decision-making. You don’t want to have twenty patterns for how your frontend code handles state. These are problems you’ll have in most software organizations, but they’ll be much more pressing in an organization using FaST.
One thing a lot of organizations under-invest in is training and communication around effective software design patterns. And conversations to make sure everyone is aligned on which approaches to use, and when. These are probably even more important in a FaST organization.
Shared code ownership is a practice that has some precedent. It would be worth spending the time to dig into how to be successful with it if you proceed with FaST.
What happens with multiple Collectives and crossing Collective boundaries?
Work that crosses Collective boundaries is essentially undefined in FaST. And large initiatives requiring high degrees of coordination are also under-specified by FaST. So you’d have to invent solutions to these situations.
Any organization large enough to have multiple Collectives using FaST will run into cross-Collective projects. The patterns for addressing these things will be similar or analogous to how you resolve it on a smaller scale. But this is largely uncharted territory, as far as I know. So you’ll need to be using some coordination models to solve these problems when they arise. It will be an act of invention.
How does FaST deal with on-call?
On-call isn’t specifically mentioned in the FaST guide. So you’ll need to invent a scheme to deal with it.
In conventional teams, the standard advice for on-call is to have each team responsible for its own operations. And to have everyone on the team on call. This implies you should have teams of at least four people so the burden isn’t too bad. The thinking is that having teams on call for their work product incentivizes them to bake reliability in. This helps them ensure they have a decent on-call schedule.
With FaST, you might create an on-call rotation that has tiers (follow this runbook and escalate if that doesn’t fix it). And you’ll need to explicitly keep a map of who is able to support what. This won’t map to your teams.
This isn’t super hard to do, but it is less common than conventional on-call practices, and will require management attention.
What about fixing bugs and support escalations?
FaST has an optional role called a “Feature Steward”. They are kind of an expert for a particular feature, and are the point of contact around that feature for stakeholders. They aren’t required to work continuously on that feature, but are required to have a continuous understanding of it.
Like on-call, you’ll need a mapping of features to people with expertise on those features. This will be important for both bugs and support escalations. And you might as well combine it with on-call as well. You’ll need some way to triage issues to the right people.

You’ll also need to make sure you have a mechanism for filling in knowledge gaps when expertise is isolated to one or two people.
One thing you’ll have to decide is your policy for fixing bugs. Do you want them to always be fixed, slowing down other feature work? Are the bugs fixed by the person who introduced them, or do you want some other scheme? And how will you determine who is responsible for triaging bugs? Probably a rotation of some sort?
Support escalations will also require some effort. The point of contact is the Feature Steward for an area. But what if the Feature Steward is on vacation? You probably want more than one person knowledgeable about each area. And what if the support question ends up requiring work? Do you just do the work, or feed it into the central priorities?
None of these are hard problems to solve, but they are management work. And everything you do will have tradeoffs of focus versus responsiveness.
What about reliability incidents and incident retrospectives?
FaST does not define how incidents are handled. Your on-call patterns will largely determine how incidents are handled, and will likely involve whoever knows how to fix the situation being pulled in to fix it.
FaST doesn’t describe how to handle incident retrospectives. I would recommend doing something like the following: schedule an incident retrospective to happen before the next Collective meeting. One of the aims of the retrospective would be to identify a few pieces of work that could be done that would either reduce the likelihood or severity of whatever caused the incident. Another would be to learn all you can from the incident.
At the Collective meeting immediately following the incident, I would share what we learned, and also make an automatic priority for the next cycle be to do some of the work identified in the retrospective.
At New Relic, we didn’t use FaST, but we had a similar policy. We called it “Don’t Repeat Incidents” (DRI). It was among the best things we ever did for reliability. The rule was that DRI work was automatically more important than other priorities. Thus, an incident always resulted in either less scope, or a deadline getting pushed back. I have a whole post on Don’t Repeat Incidents.
How do designers work in FaST?
A challenge many designers have is focusing on working with the engineering team, or doing work ahead of the engineering team. Or have them operate both ways. You’ll hear strong arguments for both ways of working.
FaST doesn’t specify how this should work, so you’ll need to decide for yourself. Do designers sign up for the teams to work on? Or are they a service organization, which work ahead on things, and act as consultants when people need something from them? You’ll need to decide. I would probably have the designers sign up and be part of the teams, but again this is an example of the type of decisions you’ll need to make when adopting FaST.
How do product managers work in FaST?
The product role in FaST is mostly to prioritize and communicate priorities. There is a lot that isn’t really described in the FaST manual about the work outside of that.
The assumption in the FaST manual seems to be that the product managers inspire and communicate, and then the engineers work on the features.
To the degree that you can, I would get engineers talking with customers, and have them gain expertise in the product area they are working in. Ideally, they would be doing the work, demoing it to customers, and getting feedback on it from them. Having the product managers facilitate that, and leveling up the engineers’ ability to do that effectively, could be a valuable part of their work.
There is a lot of flexibility in this model. You could do the typical product-to-engineering handoff, or you could have them discover and problem-solve the space together, with customers.
So as you can see, there are many gaps in FaST. You’ll need to problem-solve the rest.
FaST can run counter to a desire to allocate people to areas
When I ran a FaST Collective, one unexpected source of friction with FaST I found was that you can have some situations where parts of the organization are wanting to see a dedicated effort to be allocated against their needs. You can do this with FaST, but there can be a pull towards allocating a team or a set of people against a stream of work.
The FaST materials are full of jargon
You may find the FaST website and manual confusing. You’ll have to navigate a lot of jargon and annoying terminology to get at the gold of FaST. As an example, here’s the awful definition of FaST Agile that attempts to define the practice in version 2.12 of the FaST Guide:
“What is Fluid Scaling Technology? Fluid Scaling Technology combines Open Space Technology and Open Allocation to create a lightweight, simple to understand, and simple to master method for organising people around work - that scales. FAST is the acronym for Fluid Scaling Technology. Fluid Scaling Technology for Agile is FAST Agile.”
So. Bad. And this is very representative. You’ll see lots of references to Collectives, Value Cycles, Open Technology, Teal transformation, Theory Y, etc. This is all presented with no explanation, and really even if it were explained it wouldn’t be helpful. They’re speaking to a niche audience of agile theorists, and focusing on attribution rather than usefulness.
They also will change terminology frequently. They used to be FAST Agile, then they were FaST. I find it excrutiating.
Conclusion
So where does that leave us? Is FaST worth experimenting with?
I believe the answer to that is yes, but with caution, and in the right contexts. You can play around with it within individual teams. And if you have leadership support, experiment with it gradually within larger organizations.
Please share with me if you do experiment with it. And if you’d like help rolling it out in your organization, contact me. I’ll either help you directly, or connect you with others who can help.
Further discussion
I talked with Jim Shore about his experience with FaST on Decoding Leadership. One topic we talked about that I haven’t seen anywhere else is the role of management on FaST teams.
Thank you
Early versions of this post were… really bad. I’d like to thank Seth Falcon and Davy Stevenson for their critique. They both pointed out some major problems with the post that made me back up and rethink my approach. And they made some excellent points that I incorporated into their own sections of the post. Eventually, I rewrote most of the post, and I was much happier with the outcome. Thank you! Seth has a newsletter on engineering leadership worth checking out, and Davy (like me) does startup advising and coaching.
Jim Shore introduced me to FaST agile. He has some excellent talks on his experiences with it. And we’ve met a few times and discussed the implications and implementation of FaST. Jim is the author of The Art of Agile Development.
Image by Kanenori from Pixabay
Footnotes
Footnotes
-
I believe 150 people is probably unwieldy for a Collective. I suspect sixty people is a better maximum size. ↩