Teams often don’t handle reliability risks well. Reliability is tough to reason about.
To have a reasonable response to reliability, we share an approach called a risk matrix, with a process to create plans to manage your reliability risks.

A risk matrix is an approach teams and groups can use to help them reason about risk. They develop a list of the things they own, the dependencies they rely on, and a list of who relies on them. Then they systematically evaluate the amount of risk and impact of likely failures. And create plans to transfer, avoid, reduce, or accept each risk.
This has been used across many organizations as a high leverage approach to improving reliability.
A risk assessment framework
This document presents one approach to risk assessment as part of an overall risk mitigation strategy. The process described here is intended to be used at the team level, and the examples reflect that. But it is readily adaptable to a group and organizational level when you begin to think of teams and groups as areas of responsibility or functionality. In order to work well, this process should be recurring and required, meaning that every team should perform a risk assessment for their own services and dependencies, and that the assessment should be revisited and updated regularly (quarterly or half-yearly).
Why should we do this?
Software systems readily grow to a level of complexity that makes it difficult, if not impossible, for one person or team to hold the entire system in their head and understand how it all works together. This also means that it is hard for any one person, or team, to understand the ways that parts, or all, of the system can fail and how those failures in sub-systems will impact up and downstream components. By engaging in a recurring process of risk assessment, and mitigation, we deepen our understanding of our sub-systems, as well as the behaviors of our up and downstream dependencies. This increases the reliability of the whole system and allows us to reduce the Mean Time To Resolution (MTTR) when we do have service interruptions.
What is a risk?
In our real lives, and in software, we are faced with hazards every day. Water, gasoline, and driving are all hazards we encounter in our daily lives. They are circumstances and situations that present an opportunity for harm. A Risk is the likelihood that a hazard will cause harm. Water is the hazard, falling in and drowning is the risk.
What is a risk assessment?
The process of enumerating the hazards for a system, or subsystem, determining their likelihood of occurring (their Risk), and also the impact of their occurrence is, in broad strokes, a Risk Assessment.
A common approach is:
- Have the team sit down together (or asynchronously with whatever tools you prefer)
- Get the team to think about everything a service or component relies on, touches, uses, runs on, etc. Note these down in a shared document (often a spreadsheet is a good place)
- Sort through these to ensure that the risks identified are relevant. We could all be killed in an unexpected meteor impact but we can leave this out of the risk assessment.
- Once you are confident that you have identified the risks to your service/team/platform, take the group through each risk and reach a consensus on the Likelihood of a risk and the Impact of an occurrence of it.
- Use these evaluations to determine what, if anything, you can do about this risk.
- Create a plan to do what you can to reduce the identified risks.
- Finally, revisit your assessment, and the plans to reduce risk, regularly to ensure you are working to reduce risk and increase reliability.
How to?
There are a few tools we can bring to bear to help us with this thought exercise. I will introduce the tools and techniques before walking through the process of using them in the process outlined above.
Tools of the trade
Service catalog
This is the list or collection of services/functionality owned and operated by the business unit that is performing the risk assessment. For teams, this is commonly the list of services, libraries, tools, etc owned and operated by that team. For groups, this is often expressed as functional capabilities of a platform, or components of the platform, owned by the group.
Dependency tree
The interconnected web that forms the context your service or functionality exists within. This includes services/APIs that your service interacts with (both up and down stream), the infrastructure your components run on, the libraries imported by a project, the monitoring tools you use to operationalize your service, etc. Often, building the dependency tree is one of the more labor intensive stages but, once done and when kept up to date, it provides the jumping off point for identifying and classifying risks.
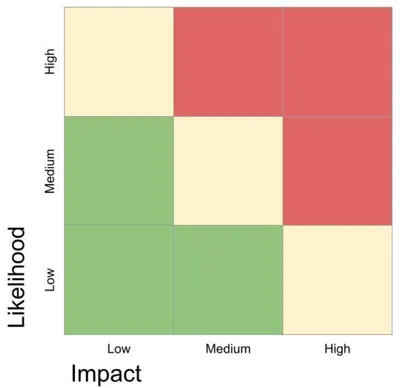
Risk matrix
The grid of Likelihood vs Impact that helps illustrate which risks present the greatest danger to your service/system. Risks with the highest likelihood and greatest impact are good areas of focus, but even less likely or less impactful risks can provide significant wins for reliability and a reduction in MTTR.
T.A.R.A
A framework for deciding what, if anything, can be done about a risk. Transfer, Avoid, Reduce, Accept or TARA outlines general categories of action for risk mitigation.
Transfer
When you transfer a risk, you are attempting to shift responsibility to some third party. This can be a vendor, another team, etc. When deciding to transfer a risk, you are not eliminating the risk, necessarily. Instead, you are saying that the best mitigation for that risk is to have some other entity be responsible for it. Running your infrastructure on AWS is a very common example of transferring the risk of running your own infrastructure to a third party.
Avoid
Eliminate the risk of encountering a hazard entirely. For example, if you rely on an external API for your service, you could avoid the risk of that API becoming unavailable by removing that dependency entirely. Avoiding a risk will often introduce other risks or dependencies, though, so be certain you understand the tradeoffs when choosing this mitigation strategy.
Reduce
This is where a lot of teams will spend their time. When you choose Reduce as your mitigation strategy, you are attempting to lower the impact or likelihood (or even both) of encountering a hazard. Increased monitoring to reduce the MTTR can reduce the impact and likelihood of an outage. Introducing redundancy to dependencies that have inconsistent reliability is another common mitigation strategy. What this looks like will vary greatly but you should always have a specific goal in mind when making attempts to Reduce a risk.
Accept
Some things you cannot do much to change and you have to Accept that. This does not absolve your team from responsibility to have a plan in place for when a hazard is encountered, but you are Accepting that the best you can do is ride out whatever storm you encounter. Again, AWS is a good example of a risk that is commonly accepted but strategies for communication and recovery after an outage occurs should be in place.
Process
The steps outlined below assume that this exercise is being done by a team. I will speak in terms of “services” and “tools” which are colloquially the sorts of things individual contributors are used to being responsible for. You can readily move up the organizational chain to perform this exercise at higher levels by substituting systems or capabilities of a platform in for services and tools.
1. Agree on Definitions
Before you can start this process you will want to come to a consensus on at least a couple definitions: Impact and Likelihood. These will be used throughout the assessment to communicate about risks, and to decide where to direct your efforts at risk mitigation. A common approach focuses on Red/Yellow/Green or Low/Medium/High for terminology.
Impact
- All of our services are unavailable for all of our customers
- Some features are unavailable or have significantly degraded performance
- All features are available but they are slower in a noticeable but minimally impactful way
Likelihood
- This happens often when we deploy
- If several other criteria are met, this will happen
- This almost never happens but could
2. Define scope and catalog services
The first step in performing a risk assessment is to understand the boundaries you are considering. Using whatever collaboration methods work best for your team, try and catalog everything your team is responsible for. A Google Sheet is often a good default. This will commonly be services, libraries, and tooling used by yourselves, and possibly other teams. Do not decompose these yet (eg service, database, infrastructure all make up some piece of functionality) as that will be done later. What is out of scope is just as important as what is in scope, in order to define and understand these boundaries, so do not be afraid to bring anything up for discussion. If your team already has an existing service catalog, go over it and ensure it is up to date. There may be things that should be added or removed since the last time you did this exercise. Finally, write the results of this down. You will need the output of this step for the next stages and having this somewhere that is discoverable by other teams can help build a shared understanding of how our sub-systems interact.
3. Identify impact
In order to rate and assess the impact of a risk, we have to be certain we understand who is impacted, and how. The first time your team goes through this exercise, you may only have theoretical ideas about this. If you have never encountered this risk before, you may only be able to guess about the impact, but do your best to think of who would be impacted and what their experience would be. This can be internal stakeholders (a team that consumes an API you support or an upstream team that sends you data), customers, or even just your team. The point is to understand “Who” and “How” not to decide whether that group or their impact “matters” yet.
4. Gauge likelihood
Similarly to impact, we have to understand the likelihood of encountering a risk in order to assess it and decide on what, if anything, to do about it. Using the definitions agreed upon earlier, come to a consensus on how likely your team thinks a given risk is to be encountered.
5. T.A.R.A.
Once you have agreed on impact and likelihood, you can use the TARA framework to decide how to classify your risk.
One thing you can do is have some heuristics that you agree upon as a team. For example:
- High-High: we work on it before anything else.
- High Impact, Low Likelihood: might be a good candidate for improved monitoring or early detection.
6. Make a plan
The most important output of this process is a plan for how to mitigate and manage risk. Each of the four classifications has a possible output and you should decide what that should be. Creating issue tracking tickets for each risk that outlines the decision about what to do can help you stay accountable for risk mitigation, and speed the process up for your future selves. For any work that will get done, it can be helpful to create separate tickets and link them to the risk tickets as risks are often persistent over time, whereas the work to mitigate them is discrete.
7. Follow up and repeat regularly
Finally, this process is most effective when it is done regularly. By going through this exercise on a recurring cadence you are able to track the evolution of risks over time, and gauge the efficacy of your mitigation strategies. When this becomes a habit for a majority of teams in an organization, you are able to track trends and evolve your risk mitigation strategies to, hopefully, continue to increase reliability and decrease Mean Time To Resolution.
Summary
A risk matrix is an approach teams and groups can use to help them reason about risk. They develop a list of the things they own, the dependencies they rely on, and a list of who relies on them. Then they systematically evaluate the amount of risk and impact of likely failures. And create plans to transfer, avoid, reduce, or accept each risk.
Thank you
Thank you to David Parrott for being willing to publish this. This document wouldn’t exist without the work of Nicholas Valler. It’s in some ways an expression of much of the work he did. So thank you Nicholas Valler! Jade contributed some edits (intro, summary, heuristics for TARA) and wanted to see it published.
Image by wastedgeneration from Pixabay